Sinnlos
Schreibe eine Antwort

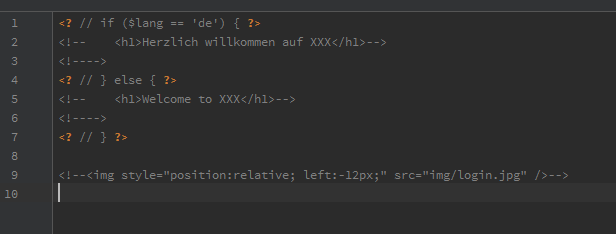
Im Zuge der „continuous integration“ setzt du bestimmt auch auf Tools wie pdepend oder phpdox. Allerdings würde ich gern nicht alle Verzeichnisse durchgehen, sondern ein paar davon exkludieren (Vendor-Zeug wie smarty oder das Zend-Framework).
Wer bei pdepend Verzeichnisse ignorieren will, der sollte es nicht wie in der Doku angegeben mit „–exclude“ versuchen, denn diese Option funktioniert schlicht einfach nicht.
Die Lösung ist bei pdepend der Parameter „–ignore=…“ dem man einfach alle Verzeichnisse kommasepariert übergibt, z.B. aus meinem ant-Script:
<arg value="--ignore=${basedir}/smarty,${basedir}/Zend" />
Bei phpdox kann man Verzeichnisse ausnehmen, wenn man diese auf die exclude-Liste des collector-Blocks setzt, den ihr in der entsprechenden phpdox.xml findet. Dieser Block kann dann z.B. so aussehen:
<collector publiconly="false" backend="parser"> <!-- @publiconly - Flag to disable/enable processing of non public methods and members --> <!-- @backend - The collector backend to use, currently only shipping with 'parser' --> <!-- <include / exclude filter for filelist generator, mask must follow fnmatch() requirements --> <include mask="*.php" /> <exclude mask="**Zend**"/> <exclude mask="**smarty**"/> <!-- How to handle inheritance --> <inheritance resolve="true"> <!-- @resolve - Flag to enable/disable resolving of inheritance --> <!-- You can define multiple (external) dependencies to be included --> <!-- <dependency path="" --> <!-- @path - path to a directory containing an index.xml for a dependency project --> </inheritance> </collector>
Der „Trick“ dabei sind die beiden * vor und nach dem Namen.
Zumindest in meinem Jenkins läuft nun alles wie es soll 😀
Der Trick ist, die Einstellungen alle VOR dem Upgrade in phpStorm7 zu exportieren und dann in phpStorm8 wieder zu importieren.
Wer diese Meldung in phpStorm bekommt, der versucht ganz offensichtlich, eine ziemlich große Datei zu öffnen, was phpStorm dann mit dieser Meldung quittiert. Und das, obwohl du eigentlich genug RAM hättest:

File size exceeds configured limit (2560000), code insight features not available
Das Dumme an der Sache ist nur, dass es über die „Settings“ nicht zu ändern ist; da kannst du lange suchen.
Die Lösung: Öffne einen Editor als Administrator und gehe in dein phpStorm/bin Verzeichnis. Dort findest du eine „PhpStorm.exe.vmoptions“. Diese öffnest du und gibt dort eine neue Zeile ein (bzw.änderst den Wert, falls es diese Zeile schon gibt):
-Didea.max.intellisense.filesize=999999
phpStorm startest du nun neu und fort ist die Meldung.
May the code be with you 😉
![SQL_Performance_Explained_cover_deutsch_hires[1]](https://www.codemercenary.de/wp-content/uploads/2014/05/SQL_Performance_Explained_cover_deutsch_hires1-e1400832554237.jpg)
SQL Performance Explained Cover
Bemessen an der Seitenzahl ist das Buch „SQL Performance Explained“ von Markus Winand eher ein dünnes und verliert sich damit in der Reihe der dicken Wälzer im (Fach-)Bücherregal. Lass dich aber von diesem Umstand nicht täuschen. Für „SQL Performance Explained“ kann man locker 2 oder 3 dicke Wälzer wegwerfen.
Dabei lernst du eigentlich nur etwas über einen kleinen Teil von Datenbanken, der sich aber dafür umso mehr bemerkbar macht: Der Index.
Markus erklärt sehr gut und sehr anschaulich, wie so ein Index aussieht, wie er funktioniert und was er bringt – Performance nämlich und das nicht zu knapp. Auf 207 Seiten (mir liegt das PDF vor) erklärt Markus sehr praxisnah und verständlich, vernachlässigt aber auch nicht die Theorie, die einer Datenbank zugrunde liegt.
Du hattest sicherlich Datenbanktheorie im Studium und kannst dich noch stöhnend an die vielen Vorlesungen erinnern, die damit einhergingen. „SQL Performance Explained“ schafft es, bezogen auf die Kernaussage „Performance“, alles in einem übersichtlichen Werk zusammen zu fassen.
Was ich persönlich direkt aus dem Buch in meiner täglichen Arbeit umsetzen konnte kam in Kapitel 2 „Die Where-Klausel“ und zwar war dies die Erklärung der „Zusammengesetzten Schlüssel“. Die Erklärung war einfach und merkbar und so konnte ich schon in mehreren Projekten davon profitieren. So lobe ich mir ein Fachbuch.
„SQL Performance Explained“ ist kein MySQL-Buch. Es ist ein Buch über Datenbanken im Allgemeinen, beinhaltet aber Beispiele u.a. für MySQL oder Oracle oder MS-SQL Server.
Falls ein bestimmtes Beispiel für eine Datenbank nicht funktioniert, weil die Datenbank diesen Befehl nicht unterstützt, dann schreibt Markus das auch gern mit in den Text. Lobenswert!
Insgesamt ein Buch, welches ich uneingeschränkt weiterempfehlen kann und werde. Ich persönlich kann es mir nicht mehr von meinem Desktop wegdenken.
Du bekommst das Buch wahlweise als Print oder PDF oder beides unter sql-performance-explained.de
Großes Lob und danke für’s schreiben, Markus!
Seit Windows XP gibt es die Möglichkeit virtuelle Laufwerke anzulegen. Ein virtuelles Laufwerk dient dazu, einen langen, komplizierten Dateipfad zu verkürzen, damit du damit z.B. besser via Konsole arbeiten kannst.
Ein Beispiel, deine Webseiten liegen im htdocs deines Webservers, dieser liegt im Programme Ordner:
C:\Programme\Apache2\htdocs
Per Konsole sehr umständlich zu erreichen, da du entweder immer wieder diesen Pfad eintippst oder dir eine Batchdatei mit entsprechedem Sprungbefehl baust.
Viel einfacher wäre es doch, einfach nur W: (wie Webseiten) einzutippen und schon bist du im htdocs Verzeichnis.
Das geht ganz einfach. Konsole auf und dort
subst w: c:\Programme\Apache2\htdocs
eingeben und fertig.
Nun steht dir mit einem simplen w: deine Webseiten zur Verfügung und du kannst W als ganz normales Laufwerk benutzen, z.B. auch aus deiner IDE heraus.
Falls du die Verknüpfung mal nicht mehr brauchst:
subst w: /d
und weg ist das Laufwerk wieder. Keine Angst, den Originalen Inhalten passiert dabei natürlich nichts, nur das virtuelle Laufwerk wird entfernt.
Am besten, du schreibst eine Batch-Datei und legst diese dann in den „Autostart“, dann wird das virtuelle Laufwerk bei jedem Start automatisch erstellt und steht zur Verfügung.
Mehr über subst findest du im TechNet von Microsoft unter diesem Link: http://technet.microsoft.com/en-us/library/bb491006.aspx
Dort findest du auch die Kommandos, die bei einem mit subst erstellten Laufwerk nicht funktionieren (z.B. format oder chkdsk).
Viel Erfolg!
Wer unter Windows entwickelt hat es oft nicht leicht, obwohl es eigentlich unter Windows alles leichter sein sollte. Aber gerade diese „alles ist leichter“ Sachen machen es einem Entwickler manchmal schwer. Schwer, den Fehler zu finden.
Beim Zend Framework (v1.x) hat man gewisse Namenskonventionen einzuhalten. Ist einfach so. Eine dieser Konventionen betrifft die Möglichkeit, Klassen automatisch zu laden. Dazu müssen diese einem bestimmten Namensmuster folgen und in einem bestimmten Verzeichnis liegen. Der Entwickler spart sich dann das lästige „require…„. Nettes Feature.
Unter Windows aber bitte aufpassen!
Schnell kommt es zu einem „Fatal Error„, weil die Datei nicht gefunden werden konnte, obwohl diese eigentlich im richtigen Verzeichnis liegt. Und im lokalen Development-System funktioniert doch alles. Server kaputt? Mitnichten!
Aufbasse: Unter Windows ist es völlig egal, welchen „case“ die Verzeichnisse und Dateinamen haben. Ein Verzeichnis „model“ ist für Windows das gleiche wie ein Verzeichnis „Model„. Das ZF würde in einem Windows-Server in beiden Fällen problemlos dein Model finden (mal vorausgesetzt, der Rest entspricht den Namenskonventionen), ein Linux-Server (und das ist der Normalfall) findet bei „model“ dein Model aber eben nicht.
Lösung: Nenn das VZ „Model„, lösch das alte VZ „model“ auf dem Server und achte nächstes Mal gut darauf. Vor allem du, Sascha 😉
![]() Wenn du vom klassischen phpUnit zu Codeception wechseln möchtest, musst du erschreckend wenige Sachen beachten. Dafür bekommst du am Ende dann die vielen Vorteile von Codeception. Ob sich das für dich und dein Projekt lohnt, musst du latürnich (sic!) selbst für dich und dein Projekt entscheiden. Mir fiel die Wahl leicht…
Wenn du vom klassischen phpUnit zu Codeception wechseln möchtest, musst du erschreckend wenige Sachen beachten. Dafür bekommst du am Ende dann die vielen Vorteile von Codeception. Ob sich das für dich und dein Projekt lohnt, musst du latürnich (sic!) selbst für dich und dein Projekt entscheiden. Mir fiel die Wahl leicht…
Wie ich schon sagte, es braucht erschreckend wenig, damit Codeception die Tests übernimmt, da sich der „unit“ Teil nicht sooo stark von phpUnit unterscheidet. Ganz im Gegenteil ruft Codeception auch phpUnit unter der Haube auf. Du hast nur den Vorteil einer einheitlichen Test-Strategie und -Sprache und musst nicht eine Vielzahl von Dialekten behalten (phpUnit, Selenium, wtf, …).
Ich nehme mal an, dass deine unit-tests bereits funktionieren und dass diese im verzeichnis „tests“ liegen. Falls nicht, das „tests“ Verzeichnis solltest du schnell mal anlegen und deine Tests von dort aus starten 😉 Dann wird’s leichter.
Also los, die ersten Erfolge sind schnell gemacht:
class_name: CodeGuy modules: enabled: [Unit, CodeHelper, Db] config: Db: populate: true cleanup: false
use Codeception\Util\Stub;
an.
\Codeception\TestCase\Test
also
class myWhateverTest extends \Codeception\TestCase\Test {
// ...
}
Damit steht nun das Grundgerüst und ihr könnt via
php codecept.phar run
eure Tests ausführen.
In meinem konkreten Fall konnte ich damit die Tests einer ZF1 Application mit Anlegen und Füllen einer Testdatenbank (MySQL) um den Faktor 8 beschleunigen. Zusätzlich kann nun recht einfach neue Tests in Codeception einfügen und die Ergebnisse stehen mir ebenfalls für Jenkins und Co zur Verfügung, teilweise mit sehr viel höherer Aussagekraft.
Viel Erfolg…
![]() Wer schon mal CSV Daten geschrieben hat kennt sicher das Problem, dass die Sonderzeichen meist nicht richtig angezeigt werden, wenn man in UTF-8 exportiert.
Wer schon mal CSV Daten geschrieben hat kennt sicher das Problem, dass die Sonderzeichen meist nicht richtig angezeigt werden, wenn man in UTF-8 exportiert.
Wer das vermeiden will muss einfach den richtigen Unicode-Header mitsenden, dieser lautet:
echo pack("CCC",0xef,0xbb,0xbf);
Dieses Kommando sendet ihr am besten nach den „header“ Kommandos, aber noch vor den Daten, dann zeigt Excel auch die richtigen Daten per Doppelklick an.
P.S. LibreOffice / OpenOffice sind von Haus aus schlau genug und stellen die Daten ohnehin richtig dar, das Problem existiert also wirklich nur für Excel.
Windows Live und Thunderbird, das hieß lange Zeit „entweder…oder“, aber nie „zusammen“. Bisher zumindest. Microsoft spendiert den Windows Live Mailkonten IMAP, einfach so, ohne „große“ Ankündigung, ohne viel Tamtam … fast hätte ich es überlesen.
Bisher unterstützte Microsoft bei den Windows Live Mailadressen nur EAS (Exchange Active Sync), was – zugegeben – wirklich schneller sein kann (und oft ist) wie das doch recht betagte IMAP. Andererseits ist EAS nicht sehr verbreitet. Zwar beherrscht jedes aktuelle Smartphone EAS mitlerweile (und mein altes Samsung Bada schon länger), schaut man sich allerdings die Desktop-Mail-Clients an sieht es oft Mau aus. Windows Live Mail ist da die erste Wahl, wenn man nicht Outlook (das richtige Outlook, nicht Express) selbst besitzt. Und lange war auch gezwungen, damit zu leben.
Nun funktioniert IMAP bei Windows Live Konten und ich zeige dir nun, wie du Thunderbird einstellt, damit die Mails syncronisiert werden und du auch an deine Termine in Thunderbird (mit Lightning) kommst.
Ich benutzte Thunderbird, du kannst, IMAP sei dank, auch irgendeinen Mailclient benutzen, der dir zusagt.
Windows Live in Thunderbird:
Für den Kalender machst du folgendes:
Viel Spaß mit Windows Live, IMAP und einem Mailclienten deiner Wahl.
{kind=link}